认识进程
进程
进程(Process)是指正在运行的程序的实例。当一个程序被执行时,操作系统会为该程序创建一个新的进程,并为其分配所需的资源,如内存空间、文件描述符等。进程是操作系统资源分配的最小单元。
每个进程都有一个唯一的标识符(PID,Process ID),用于在操作系统中标识和管理进程。
并发
CPU是支持分时调度的,以时间片的形式来跑指令集。OS层面操作系统会轮换调度进程的一部分指令集给CPU运行。由于CPU的执行效率非常高,时间片非常短,在各个任务之间快速地切换,给人的感觉就是多个任务在同时进行,这也就是我们所说的并发。

线程
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式。随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了,于是就发明了线程。
线程是计算机中最基本的执行单位,它是操作系统能够进行运算调度的最小单位。
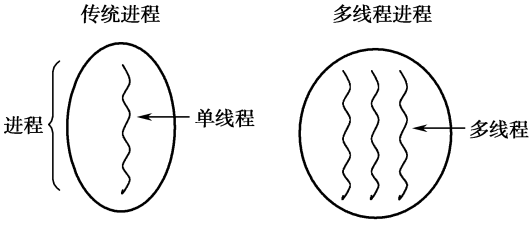
一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。
多线程是目前最流行的并发场景的解决方案,由于线程更加轻量级,创建和销毁的成本都很低。并且线程之间通信以及共享内存非常方便,和多进程相比开销要小得多。
监控进程状态
ps命令
ps命令可用于静态展示当前正在运行的进程信息。
常用选项如表:
| 选项 | 解释 |
|---|---|
| -aux | 显示所有进程的详细信息,包括CPU和内存占用等。 |
| -e | 显示所有进程,包括其他用户的进程。 |
| -f | 显示完整格式的进程信息。 |
查询当前进程。
|
|
ps -aux为常用组合,用于查看进程的用户、PID、占用cpu百分比、占用内存百分比、状态、执行的命令等。
ps状态及描述:
| 状态 | 描述 |
|---|---|
| USER | 启动进程的用户。 |
| PID | 进程运行的ID号。 |
| %CPU | 进程占用CPU百分比。 |
| %MEM | 进程占用内存百分比。 |
| VSZ | 进程占用虚拟内存的大小(单位KB)。 |
| RSS | 进程占用物理内存实际大小(单位KB)。 |
| TTY | 进程是由哪个终端运行启动的,tty1、pts/0等,?表示内核程序与终端无关。 |
| STAT | 进程运行过程中的状态。 |
| START | 进程启动的时间。 |
| TIME | 进程占用的CPU的总时间(0表示还没超过秒)。 |
| COMMAND | 程序执行的指令,[ ]内输入内核态的进程。没有[ ]的是用户态的进程。 |
STAT的状态及描述。
| STAT基本状态 | 描述 | STAT状态+符号 | 描述 |
|---|---|---|---|
| R | 进程运行。 | s | Ss进程的领导者,父进程。 |
| S | 可中断睡眠。 | < | 进程运行在高优先级上,S<优先级较高的进程。 |
| T | 进程被暂停。 | N | 进程运行在低优先级上,SN优先级较低的进程。 |
| D | 不可中断的睡眠。 | + | 当前进程运行在前台,R+表示进程在前台运行。 |
| Z | 僵尸进程。 | l | 进程是多线程的,Sl表示进程是以线程方式运行的。 |
查看进程状态
在终端1上运行vim命令。
|
|
在终端2上通过ps命令查看进程的状态
|
|
在终端1上挂起vim命令,按下:ctrl+z,回到终端2再次运行ps命令查看状态。
|
|
不可中断状态
在终端1上使用tar对文件进行打包。
[root@localhost ~]# tar czf test.tar.gz /etc/ /usr/ /var/
在终端2上不断查看状态。
|
|
top命令
使用top命令查看当前的进程状态(动态)。
|
|
第一行解释及说明。
top - 02:26:15 up 2:01, 3 users, load average: 0.00, 0.01, 0.08
| 状态 | 说明 |
|---|---|
| 02:26:15 | 当前系统时间。 |
| 2:01 | 系统运行时长。 |
| 3 users | 当前有3个用户(终端)连接到系统。 |
| load average | 平均负载。 |
| 0.00 | 一分钟内平均负载。 |
| 0.01 | 五分钟内平均负载。 |
| 0.08 | 十五分内平均负载。 |
第二行解释及说明。
Tasks: 109 total, 1 running, 108 sleeping, 0 stopped, 0 zombie
| 状态 | 说明 |
|---|---|
| 109 total | 当前进程总数。 |
| 1 running | 正在运行的进程数量(R)。 |
| 108 sleeping | 睡眠的进程数(S)。 |
| 0 stopped | 停止,挂起的进程数(T)。 |
| 0 zombie | 僵尸进程数。 |
第三列解释及说明
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
| 状态 | 说明 |
|---|---|
| 0.0 us | 系统用户进程使用CPU百分比。 |
| 0.2 sy | 内核中的进程占用CPU百分比,通常内核是于硬件进行交互。 |
| 0.0 ni | 优先级的进程占用cpu的百分比。 |
| 99.8 id | 空闲CPU的百分比。 |
| 0.0 wa | CPU等待IO完成的时间。 |
| 0.0 hi | 硬中断,占的CPU百分比。 |
| 0.0 si | 软中断,占的CPU百分比。 |
| 0.0 st | 比如虚拟机占用物理CPU的时间。 |
top常见指令。
| 指令 | 含义 |
|---|---|
| h | 查看帮助。 |
| 1 | 数字1,显示所有CPU核心的负载。 |
| b | 高亮显示处于R状态的进程。 |
| M | 按内存使用百分比排序输出。 |
| P | 按CPU使用百分比排序输出。 |
管理进程状态
当程序正在运行,我们可以使用kill命令对进程发送关闭信号,停止进程。
列出kill当前系统所支持的信号。
|
|
其中比较常用的信号有1、9、15
| 数字编号 | 信号含义 | 信号翻译 |
|---|---|---|
| 1 | SIGHUP | 通常用来重新加载配置文件。 |
| 9 | SIGKILL | 强制杀死进程 |
| 15 | SIGTERM | 终止进程,默认kill使用该信号 |
使用kill命令杀死指定的进程。
|
|
kill -1为发送从在信号,当修改了配置文件是,可通过这条命令重新加载。
|
|
发送停止信号,停止正在运行的服务。
|
|
kill -9为发送强制停止信号,当无法停止服务时,可强制终止信号。
|
|
kill -9 PID可强制杀死进程 ,对于mysql这类有状态的进程慎用。
在Linux中,除了kill我们还可以用killall和pkill对进程进行管理。killall和pkill无需指定进程的PID就可以结束服务所都应的所有进程。
通过killall结束nginx的所有进程。
|
|
通过pkill结束nginx的所有进程。
|
|
使用pkill踢出从远程登录到本机的用户,终止pts/1上所有进程,并且bash也结束(用户被强制退出)
|
|
后台进程
通常进程都会在终端前台运行,一旦关闭终端,进程也会随着结束,那么此时我们就希望进程能在后台运行,就是将在前台运行的进程放入后台运行,这样及时我们关闭了终端也不影响进程的正常运行。
早期的时候大家都选择使用&符号将进程放入后台,然后在使用jobs、bg、fg等方式查看进程状态,但太麻烦了。在实际生成过程中screen使用起来更方便。
安装screen工具。
|
|
开启一个screen窗口,指定名称。
|
|
在新的窗口中可执行命令。
|
|
平滑的退出screen,但不会终止screen中的任务。注意: 如果使用exit才算真的关闭screen窗口。`
|
|
查看当前正在运行的screen任务。
|
|
可通过screen名称或ID进入正在运行的screen。
|
|
进程优先级
优先级指的是优先享受资源,优先级高,CPU会优先处理。
在启动进程时,为不同的进程使用不同的调度策略。
nice值越高: 表示优先级越低,例如+19,该进程容易将CPU使用量让给其他进程。
nice 值越低: 表示优先级越高,例如-20,该进程更不倾向于让出CPU。
查看进程优先级
使用top可以查看nice优先级。 NI: 实际nice级别,默认是0。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 125476 3116 1768 S 0.0 0.3 0:25.64 systemd
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
使用ps查看进程优先级。
[root@localhost ~]# ps axo command,nice
COMMAND NI
/usr/lib/systemd/systemd -- 0
[kworker/0:0H] -20
[rcu_sched] 0
[lru-add-drain] -20
调整进程优先级
nice指定程序的优先级。语法格式nice -n 优先级数字 进程名称。
[root@localhost ~]# nice -n -5 vim test
[root@localhost ~]# ps axo command,nice | grep vim
vim test -5
通过nice修改程序的优先级,最终的优先级和ssh的优先级有关系。比如当前ssh的nice是-20,当把vim的nice设置为5时,实际的vim的优先级为-15
renice命令修改一个正在运行的进程优先级。语法格式renice -n 优先级数字 进程pid
修改ssh的nice
[root@localhost ~]# ps axo pid,command,nice | grep ssh
2318 /usr/sbin/sshd -D 0
27994 sshd: root@pts/0 0
29478 grep --color=auto ssh 0
[root@localhost ~]# renice -n -20 2318
2318 (process ID) old priority 0, new priority -20
重新登陆后,ssh的nice都变为了-20
[root@localhost ~]# ps axo pid,command,nice | grep ssh
2318 /usr/sbin/sshd -D -20
29533 sshd: root@pts/2 -20
29591 sshd: root@pts/0 -20
为了防止因服务器假死出现ssh连接服务器困难的情况,可将ssh的nice调整为-20
系统平均负载
平均负载概念
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU使用率并没有直接关系。
所谓可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们常用ps命令看到的,处于R状态(Running或Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
既然平均的是活跃进程数,那么最理想的,就是每个CPU上都刚好运行着一个进程,这样每个CPU都得到了充分利用。比如当平均负载为2时,意味着什么呢?
- 在
4个CPU的系统上,意味着CPU有50的空闲。 - 在只有
2个CPU的系统上,意味着所有的CPU都刚好被完全占用。 - 在只有
1个CPU的系统中,则意味着有一半的进程竞争不到CPU。
平均负载阙值
平均负载有三个数值,分别表示1分钟、5分钟、15分钟内的平均负载。我们通过这三个值,可全面的看出目前系统的负载情况。
-
如果
1分钟、5分钟、1分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。 -
如果
1分钟的值远小于15分钟的值,就说明系统最近1分钟的负载在减少,而过去15分钟内却有很大的负载。 -
如果
1分钟的值远大于15分钟的值,就说明最近1分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦1分钟的平均负载接近或超过了CPU的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
在举个例子,假设我们在有2个CPU系统上看到平均负载为2.73,6.90,12.98。那么说明:
-
在过去
1分钟内,每个CPU有36%的超载(2.73-2)/2=36%; -
在过去
5分钟内,每个CPU有245%的超载(6.90-2)/2=245%; -
过去
15分钟内,每个CPU有549%的超载,(12.98-2)/2=549%。
但从整体趋势来看,系统的负载是在逐步的降低。
当平均负载高于CPU数量70%的时候,我们就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
影响平均负载的因素
哪些情况会导致平均负载升高呢?
平均负载案例分析实战
下面,我们以三个示例分别来看这三种情况,并用 stress、mpstat、pidstat 等工具,找出平均负载升高的根源。 stress是Linux系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。 mpstat是多核 CPU 性能分析工具,用来实时查看每个CPU的性能指标,以及所有 CPU 的平均指标。 pidstat是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
如果出现无法使用mpstat、pidstat命令查看%wait指标建议更新下软件包
[root@localhost ~]# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm
[root@localhost ~]# rpm -Uvh sysstat-11.7.3-1.x86_64.rpm
CPU 密集型进程
第一个终端运行stress命令,模拟一个CPU 使用率100% 的场景。
[root@localhost ~]# stress --cpu 1 --timeout 600
stress: info: [30367] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
# --cpu 产生n个进程,每个进程都反复不停的计算随机数的平方根
# --timeout 指定运行N秒后停止
通过top查看,CPU的使用率为100%,平均负载在不断的增加。
[root@localhost ~]# top
top - 17:33:47 up 10 days, 7:53, 3 users, load average: 4.76, 2.14, 0.84
Tasks: 88 total, 4 running, 84 sleeping, 0 stopped, 0 zombie
%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1014888 total, 143192 free, 125864 used, 745832 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 671156 avail Mem
在第三个终端运行mpstat查看CPU 使用率的变化情况。
[root@localhost ~]# mpstat -P ALL 5
# -P ALL表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
Linux 3.10.0-957.21.3.el7.x86_64 (ennan) 08/22/2019 _x86_64_ (1 CPU)
# 单核CPU,所以只有ALL和0,利用率为100%
05:32:26 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
05:32:31 PM all 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:32:31 PM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
使用pidstat工具,间隔5秒后输出一组数据。
[root@localhost ~]# pidstat -u 5 1
Linux 3.10.0-957.21.3.el7.x86_64 (ennan) 08/22/2019 _x86_64_ (1 CPU)
# 通过以下数据可看出stress所占用的CPU最高
05:49:09 PM UID PID %usr %system %guest %wait %CPU CPU Command
05:49:14 PM 0 2389 0.00 0.20 0.00 0.00 0.20 0 NetworkManager
05:49:14 PM 0 2616 0.20 0.00 0.00 0.00 0.20 0 bcm-agent
05:49:14 PM 0 30644 99.00 0.00 0.00 1.20 99.00 0 stress
05:49:14 PM 0 30658 0.00 0.20 0.00 0.00 0.20 0 pidstat
**问题分析:**通过以上实验,我们可以看出平均负载和cpu的使用率再不断的提升,但是iowait为0。而stress占用了大量的CPU(99%),从而可以分析出,是stree占用CPU过高导致平均负载的升高。
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程
运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync
[root@localhost ~]# stress --io 1 --timeout 600s
通过top命令可看到平均负载在不断的升高,wa也会升高。
[root@localhost ~]# top
top - 18:27:55 up 10 days, 8:48, 3 users, load average: 3.93, 1.82, 0.99
Tasks: 92 total, 2 running, 90 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.7 us, 94.0 sy, 0.0 ni, 0.0 id, 4.0 wa, 0.0 hi, 0.0 si, 0.3 st
KiB Mem : 1014888 total, 101312 free, 129256 used, 784320 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 667648 avail Mem
通过pidstat可看出stress占用较多的资源。
[root@localhost ~]# pidstat -u 5 1
# 间隔5秒后输出一组数据
Linux 3.10.0-957.21.3.el7.x86_64 (ennan) 08/22/2019 _x86_64_ (1 CPU)
06:33:55 PM UID PID %usr %system %guest %wait %CPU CPU Command
06:34:00 PM 0 31173 0.00 20.96 0.00 59.28 20.96 0 stress
06:34:00 PM 0 31174 0.00 23.55 0.00 55.49 23.55 0 stress
06:34:00 PM 0 31175 0.20 31.54 0.00 63.67 31.74 0 stress
06:34:00 PM 0 31176 0.00 21.96 0.00 56.29 21.96 0 stress
**问题分析:**通过top中的wa及pidstat中的wait可分析出,是I/0过高导致了平均负载的提升。
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量进程的场景
使用 stress,模拟的是 4 个进程。
[root@localhost ~]# stress -c 4 --timeout 600
通过top命令可看到平均负载在不断的升高,CPU利用率也再升高。
[root@localhost ~]# top
top - 19:15:18 up 10 days, 9:35, 3 users, load average: 8.77, 5.68, 3.19
Tasks: 89 total, 5 running, 83 sleeping, 0 stopped, 1 zombie
%Cpu(s): 99.7 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.3 st
KiB Mem : 1014888 total, 94984 free, 123008 used, 796896 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 674120 avail Mem
通过pidstat可看出stress占用较多的资源。
[root@localhost ~]# pidstat -u 5 1
# 间隔5秒后输出一组数据
Linux 3.10.0-957.21.3.el7.x86_64 (ennan) 08/22/2019 _x86_64_ (1 CPU)
07:15:58 PM UID PID %usr %system %guest %wait %CPU CPU Command
07:16:03 PM 0 31503 24.95 0.00 0.00 75.25 24.95 0 stress
07:16:03 PM 0 31504 24.75 0.00 0.00 75.65 24.75 0 stress
07:16:03 PM 0 31505 25.15 0.00 0.00 76.05 25.15 0 stress
07:16:03 PM 0 31506 24.95 0.00 0.00 74.45 24.95 0 stress
**问题分析:**4 个进程在争抢 1 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
